除法
下面是一个非常简单的函数
int f(int a)
{
return a/9;
};
14.1 x86
以一种十分容易预测的方式编译的
_a$ = 8 ; size = 4
_f PROC
push ebp
mov ebp, esp
mov eax, DWORD PTR _a$[ebp]
cdq ; sign extend EAX to EDX:EAX
mov ecx, 9
idiv ecx
pop ebp
ret 0
_f ENDP
IDIV 有符号数除法指令 64位的被除数分存在两个寄存器EDX:EAX,除数放在单个寄存器ECX中。运算结束后,商放在EAX,余数放在EDX。f()函数的返回值将包含在eax寄存器中,也就是说,在进行除法运算之后,值不会再放到其他位置,它已经在合适的地方了。正因为IDIV指令要求被除数分存在EDX:EAX里,所以需要在做除法前用CDQ指令将EAX中的值扩展成64位有符号数,就像MOVSX指令(13.1.1)所做的一样。如果我们切换到优化模式(/0x),我们会得到
清单14.2:MSVC优化模式
_a$ = 8 ; size = 4
_f PROC
mov ecx, DWORD PTR _a$[esp-4]
mov eax, 954437177 ; 38e38e39H
imul ecx
sar edx, 1
mov eax, edx
shr eax, 31 ; 0000001fH
add eax, edx
ret 0
_f ENDP
这里将除法优化为乘法。乘法运算要快得多。使用这种技巧可以得到更高效的代码。
在编译器优化中,这也称为“strength reduction”
GCC4.4.1甚至在没有打开优化模式的情况下生成了和在MSVC下打开优化模式的生成的几乎一样的代码。
清单14.3 GCC 4.4.1 非优化模式
public f
f procnear
arg_0 = dword ptr 8
push ebp
mov ebp, esp
mov ecx, [ebp+arg_0]
mov edx, 954437177 ; 38E38E39h
mov eax, ecx
imul edx
sar edx, 1
mov eax, ecx
sar eax, 1Fh
mov ecx, edx
sub ecx, eax
mov eax, ecx
pop ebp
retn
f endp
14.2 ARM
ARM处理器,就像其他的“纯”RISC处理器一样,缺少除法指令,缺少32位常数乘法的单条指令。利用一个技巧,通过加法,减法,移位是可以实现除法的。 这里有一个32位数被10(20,3.3常量除法)除的例子,输出商和余数。
; takes argument in a1
; returns quotient in a1, remainder in a2
; cycles could be saved if only divide or remainder is required
SUB a2, a1, #10 ; keep (x-10) for later
SUB a1, a1, a1, lsr #2
ADD a1, a1, a1, lsr #4
ADD a1, a1, a1, lsr #8
ADD a1, a1, a1, lsr #16
MOV a1, a1, lsr #3
ADD a3, a1, a1, asl #2
SUBS a2, a2, a3, asl #1 ; calc (x-10) - (x/10)*10
ADDPL a1, a1, #1 ; fix-up quotient
ADDMI a2, a2, #10 ; fix-up remainder
MOV pc, lr
14.2.1 Xcode优化模式(LLVM)+ARM模式
__text:00002C58 39 1E 08 E3 E3 18 43 E3 MOV R1, 0x38E38E39
__text:00002C60 10 F1 50 E7 SMMUL R0, R0, R1
__text:00002C64 C0 10 A0 E1 MOV R1, R0,ASR#1
__text:00002C68 A0 0F 81 E0 ADD R0, R1, R0,LSR#31
__text:00002C6C 1E FF 2F E1 BX LR
运行原理
这里的代码和优化模式的MSVC和GCC生成的基本相同。显然,LLVM在产生常量上使用相同的算法。
善于观察的读者可能会问,MOV指令是如何将32位数值写入寄存器中的,因为这在ARM模式下是不可能的。实际上是可能的,但是,就像我们看到的,与标准指令每条有四个字节不同的是,这里的每条指令有8个字节,其实这是两条指令。第一条指令将值0x8E39装入寄存器的低十六位,第二条指令是MOVT,它将0x383E装入寄存器的高16位。IDA知道这些顺序,并且为了精简紧凑,将它精简转换成一条伪代码。
SMMUL (Signed Most Significant Word Multiply)实现两个32位有符号数的乘法,并且将高32位的部分放在r0中,弃掉结果的低32位部分。
MOV R1,R0,ASR#1 指令算数右移一位。
ADD R0,R1,LSR#31 R0=R1+R0>>32
事实上,在ARM模式下,并没有单独的移位指令。相反,像(MOV,ADD,SUB,RSB)3 这样的数据处理指令,第二个操作数需要被移位。ASR表示算数右移,LSR表示逻辑右移。
14.2.2 优化 Xcode(LLVM)+thumb-2 模式
MOV R1, 0x38E38E39
SMMUL.W R0, R0, R1
ASRS R1, R0, #1
ADD.W R0, R1, R0,LSR#31
BX LR
在thumb模式下有些单独的移位指令,这个例子中使用了ASRS(算数右移)
14.2.3 Xcode非优化模式(LLVM) keil模式
非优化模式 LLVM不生成我们之前看到的那样的代码,它插入了一个调用库函数的call __divsi3
关于keil:通常插入一个调用库函数的call __aeabi_idivmod
14.3 工作原理
下面展示的是怎样用乘法来优化除法,其中借助了2^n的阶乘
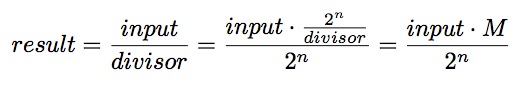
M是一个magic系数
M的计算过程
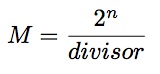
因此这些代码片段通常具有这样的形式
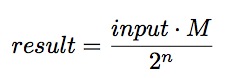
n可以是任意数,可能是32(那么这样运算结果的高位部分从EX或者RDX寄存器中获取),可能是31(这种情况下乘法结果的高位部分结果右移)
n的选取是为了减少错误。
当进行有符号数除法运算,乘法结果的符号也会被放到输出结果中。
下面来看看不同之处。
int f3_32_signed(int a)
{
return a/3;
};
unsigned int f3_32_unsigned(unsigned int a)
{
return a/3;
};
在无符号版本的函数中,magic系数是0xAAAAAAAB,乘法结果被2^3*3除。
在有符号版本的函数中,magic系数是0x55555556,乘法结果被2^32除。
符号来自于乘法结果:高32位的结果右移31位(将符号位放在EAX中最不重要的位置)。如果最后结果为负,则会设置为1。
清单14.4:MSVC 2012/OX
_f3_32_unsigned PROC
mov eax, -1431655765 ; aaaaaaabH
mul DWORD PTR _a$[esp-4] ; unsigned multiply
shr edx, 1
mov eax, edx
ret 0
_f3_32_unsigned ENDP
_f3_32_signed PROC
mov eax, 1431655766 ; 55555556H
imul DWORD PTR _a$[esp-4] ; signed multiply
mov eax, edx
shr eax, 31 ; 0000001fH
add eax, edx ; add 1 if sign is negative
ret 0
_f3_32_signed ENDP
14.4 得到除数
14.4.1 变形#1
通常,代码具有这样一种形式
mov eax, MAGICAL CONSTANT
imul input value
sar edx, SHIFTING COEFFICIENT ; signed division by 2^x using arithmetic shift right
mov eax, edx
shr eax, 31
add eax, edx
我们将32位的magic系数表示为M,移位表示为C,除数表示为D
我们得到的除法是
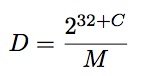
举个例子
清单14.5:优化模式 MSVC2012
mov eax, 2021161081 ; 78787879H
imul DWORD PTR _a$[esp-4]
sar edx, 3
mov eax, edx
shr eax, 31 ; 0000001fH
add eax, edx
即
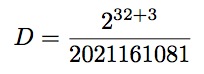
比32位的数字大,为了方便,于是我们使用用Wolfram Mathematica软件。
In[1]:=N[2^(32+3)/2021161081]
Out[1]:=17.
因此例子中的代码得到结果是17。
对于64位除法来说,原理是一样的,但是应该使用2^64来代替2^32。
uint64_t f1234(uint64_t a)
{
return a/1234;
};
清单14.7:MSVC2012/Ox
f1234 PROC
mov rax, 7653754429286296943 ; 6a37991a23aead6fH
mul rcx
shr rdx, 9
mov rax, rdx
ret 0
f1234 ENDP
清单14.8:Wolfram Mathematica
In[1]:=N[2^(64+9)/16^^6a37991a23aead6f]
Out[1]:=1234.
14.4.2 变形#2
忽略算数移位的变形也是存在的
mov eax, 55555556h ; 1431655766
imul ecx
mov eax, edx
shr eax, 1Fh
更加简洁
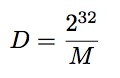
在这个例子中
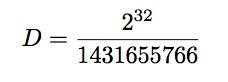
再用一次Wolfram Mathematica
In[1]:=N[2^32/16^^55555556]
Out[1]:=3.
得到的除数是3


 雷达卡
雷达卡 发表于 2024-12-17 21:58:21
发表于 2024-12-17 21:58:21
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶