循环在 release 和 debug 版有重大区别
循环的难点在于处理代码外提和代码内联
DEBUG版
do while
do while 是3种循环中 仅跳一次的,而且判断条件是正向的
定式:
DO_BEGIN :
..........
jxx DO_BEGIN
DO_END :
do while 的循环条件是正方向 条件还小于等于 ,那么就是 while 里面的的条件小于等于,因为他的语义和汇编一致,满足条件就转移
int main(int argc, char* argv[])
{
int nSum = 0;
int i = 1;
do
{
nSum = nSum + i;
i++;
} while (i<=100);
printf("%d\r\n",nSum);
return 0;
}
反汇编代码
mov [ebp+var_4], 0
mov [ebp+var_8], 1
loc_40F986:
mov eax, [ebp+var_4]
add eax, [ebp+var_8]
mov [ebp+var_4], eax
mov ecx, [ebp+var_8]
add ecx, 1 ; i+1
mov [ebp+var_8], ecx
cmp [ebp+var_8], 64h ;
jle short loc_40F986 ; 跳转往上跳
mov edx, [ebp+var_4]
push edx
push offset Format ; "%d\r\n"
call _printf
分析: 往上跳可以直接还原成 do while
while
定式:
WHILE_BEGIN :
jxx WHILE_END
.....
jmp WHILE_BEGIN ;往上跳就是while循环,往下跳就是 if else
WHILE_END:
jxx 的条件 跟 while 相反 jxx是满足条件条件跳走,while 是满足条件执行,2者相反
int main(int argc, char* argv[])
{
int nSum = 0;
int i = 1;
while (i<=100)
{
nSum = nSum + i;
i++;
}
printf("%d\r\n",nSum);
return 0;
}
反汇编代码
mov [ebp+var_4], 0
mov [ebp+var_8], 1
loc_401036: ; WHILE_BEGIN:
cmp [ebp+var_8], 64h
jg short loc_401050
mov eax, [ebp+var_4]
add eax, [ebp+var_8]
mov [ebp+var_4], eax
mov ecx, [ebp+var_8]
add ecx, 1
mov [ebp+var_8], ecx
jmp short loc_401036 ;往上跳,所以是 while
loc_401050: ; WHILE_END:
mov edx, [ebp+var_4]
push edx
push offset Format ; "%d\r\n"
call _printf
for
定式:
FOR_INIT: ; for 的 步长变量初始化
.....
jmp FOR_CMP
FOR_SETP: ;for 的步长
.....
FOR_CMP: ;for 的条件比较
.....
jmp FOR_END
FOR_BODY: ; 循环体内容
......
jmp FOR_STEP
FOR_END: ; for 结束
如果没有比较部分就是一个永真循环,就必须有 break
for 如果不写全就跟 while 一样
int main(int argc, char* argv[])
{
int nSum = 0;
for (int i = 1;
i<=100;
i++)
{
nSum = nSum + i;
}
printf("%d\r\n",nSum);
return 0;
}
反汇编代码
mov [ebp+var_4], 0
mov [ebp+var_8], 1 ;初值部分
jmp short loc_401041 ;跳转到比较
loc_401038: ;步长部分
mov eax, [ebp+var_8]
add eax, 1
mov [ebp+var_8], eax
loc_401041: 比较部分
cmp [ebp+var_8], 64h ; 'd'
jg short loc_401052 ;跳转到结束
;body部分
mov ecx, [ebp+var_4]
add ecx, [ebp+var_8]
mov [ebp+var_4], ecx
jmp short loc_401038 ;跳转到步长
loc_401052: ;for 结束
mov edx, [ebp+var_4]
push edx
push offset Format ; "%d\r\n"
call _printf
break, continue
者2个肯定 有 if ,不然他们下面的代码将无法执行(不可达分支)
break 是 跳转到 for 结尾
continue 是 跳转到 for 步长
int main(int argc, char* argv[])
{
int nSum = 0;
for (int i = 1;i<=100;i++)
{
if(sum > 50){
break;
}
if(i % 6 == 5){
continue;
}
nSum = nSum + i;
}
printf("%d\r\n",nSum);
return 0;
}
反汇编代码
mov [ebp+var_4], 0
mov [ebp+var_8], 1
jmp short loc_401041
loc_401038:
mov eax, [ebp+var_8]
add eax, 1
mov [ebp+var_8], eax
loc_401041:
cmp [ebp+var_8], 64h ; 'd'
jg short loc_40106C
cmp [ebp+var_4], 32h ;
jle short loc_40104F
jmp short loc_40106C //跳到 for 结尾
loc_40104F:
mov eax, [ebp+var_8]
cdq
mov ecx, 6
idiv ecx
cmp edx, 5
jnz short loc_401061
jmp short loc_401038 //跳到 for 步长
loc_401061:
mov edx, [ebp+var_4]
add edx, [ebp+var_8]
mov [ebp+var_4], edx
jmp short loc_401038
loc_40106C:
mov eax, [ebp+var_4]
push eax
push offset Format ; "%d\r\n"
call _printf
有时候 continue 可以还原出 if else 的效果
while (i <= 100)
{
if( i % 4 == 0)
{
printf("\r\n");
i++;
continue ;
}
nSum = nSum + i;
i++;
}
=>
while (i <= 100)
{
if( i % 4 == 0)
{
printf("\r\n");
i++;
}
else
{
nSum = nSum + i;
i++;
}
}
RELEASE
release 会把 3种循环都优化成 do while 因为 do while 效率高
优化方法1 : 强度削弱
优化成 do while
do while
int main(int argc, char* argv[])
{
int nSum = 0;
int i = 1;
do
{
nSum = nSum + i;
i++;
} while (i<=100);
printf("%d\r\n",nSum);
return 0;
}
反汇编代码:
xor ecx, ecx
mov eax, 1
loc_401007:
add ecx, eax
inc eax
cmp eax, 64h ; 'd'
jle short loc_401007
push ecx
push offset aD ; "%d\r\n"
call sub_401020
add esp, 8
xor eax, eax
retn
WHILE
int main(int argc, char* argv[])
{
int nSum = 0;
int i = 1;
while (i<=100)
{
nSum = nSum + i;
i++;
}
printf("%d\r\n",nSum);
return 0;
}
反汇编代码
xor ecx, ecx
mov eax, 1
loc_401007:
add ecx, eax
inc eax
cmp eax, 64h ; 'd'
jle short loc_401007
push ecx
push offset aD ; "%d\r\n"
call sub_401020
add esp, 8
xor eax, eax
retn
FOR
int main(int argc, char* argv[])
{
int nSum = 0;
for (int i = 1;i<=100;i++)
{
nSum = nSum + i;
}
printf("%d\r\n",nSum);
return 0;
}
反汇编代码:
xor ecx, ecx
mov eax, 1
loc_401007:
add ecx, eax
inc eax
cmp eax, 64h ; 'd'
jle short loc_401007 ;循环上跳
push ecx
push offset aD ; "%d\r\n"
call sub_401020
add esp, 8
xor eax, eax
retn
可以看出 3种循环的反汇编代码是一样的,但是 do while 至少会跑一次 ,跟 for 和 while 是不等价的,上面等价是因为常量传播了, 1 <= 100 ,所以编译器知道至少得跑一次
while (i<=argc)
{
nSum = nSum + i;
i++;
}
就类似于
if ( i<=argc )
{
do
{
} while (i<=argc);
}
这样就避免了 第一次的问题,这样虽然看起来是两跳,但是 在循环体内部就只有 1跳了
碰到这种定式是,不能直接还原成 while 或者 for 循环,必须先判断 2次 比较有没有相关性,即 是不是相同的变量比较, 如果有相关性,还原成 for 或 while 就看自己的选择
GCC 或者其他编译器
也是把for 或 while 优化成 do while ,但是比较粗暴
jmp LOOP_CMP
LOOP_BEGIN:
......
......
LOOP_CMP:
jxx LOOP_BEGIN
LOOP_END:
强度削弱
int main(int argc, char* argv[])
{
int nSum = 0;
int i = 1;
while (i <= argc)
{
nSum = i * argc;
i++;
}
printf("%d\r\n",nSum);
return 0;
}
反汇编代码:
mov ecx, [esp+argc]
xor edx, edx
cmp ecx, 1
jl short loc_401018
push esi
mov eax, ecx
mov esi, ecx
loc_401010:
mov edx, eax
add eax, ecx
dec esi
jnz short loc_401010
pop esi
loc_401018:
push edx
push offset aD ; "%d\r\n"
call sub_401030
add esp, 8
xor eax, eax
retn
分析: 上面可以看到.循环体里面并没有乘法,
那是因为编译器发现 nSum = i * argc; => nSum = nSum + argc; 因此把乘法转成了 加法
如果 i 不是 1开始, 只需要 最开始 nSum = i * argc; 循环里面再做 ++ ,这种可以直接按编译器的优化
优化方法二: 代码外提
int main(int argc, char* argv[])
{
int nSum = 0;
int i = 1;
while (i<=argc / 7)
{
nSum = nSum + i;
i++;
}
printf("%d\r\n",nSum);
return 0;
}
反汇编代码:
push esi
mov esi, [esp+4+argc]
;除法
mov eax, 92492493h
push edi
imul esi
add edx, esi
mov ecx, 1
sar edx, 2
mov eax, edx
xor edi, edi
shr eax, 1Fh
add edx, eax
cmp edx, ecx
jl short loc_40102B
loc_401024: ;循环体
add edi, ecx
inc ecx
cmp ecx, edx
jle short loc_401024
loc_40102B:
push edi
push offset aD ; "%d\r\n"
call printf
add esp, 8
xor eax, eax
pop edi
pop esi
retn
分析: 可以看到,编译器把除法提到 循环体外面去了,循环体内部并没有做除法
优化方法三:减少循环次数
高版本才有,低版本是没有的
int main(int argc, char* argv[])
{
int nSum = 0;
int i = 1;
while (i <= 100)
{
nSum = nSum + i;
i++;
}
printf("%d\r\n", nSum);
return 0;
}
反汇编代码:
push esi
push edi
xor ecx, ecx
xor edx, edx
xor esi, esi
mov eax, 1
xor edi, edi
nop ; 这里也可以是等价 nop的指令,让循环的首地址在 %16 = 0 的位置
loc_401050:
inc edi
add esi, 2
add edx, 3
; 分成四段相加
add ecx, eax
add edi, eax
add esi, eax
add edx, eax
add eax, 4 ;每次循环 + 4
cmp eax, 64h ; 'd'
jle short loc_401050
;在把四段的值加在一起
lea eax, [edx+esi]
add eax, edi
add ecx, eax
push ecx
push offset _Format ; "%d\r\n"
call _printf
分析:
while (i <= 100)
{
nSum = nSum + i;
i++;
}
=>
while (i <= 100)
{
nSum = nSum + i;
nSum = nSum + i+1;
nSum = nSum + i+2;
nSum = nSum + i+3;
i= i + 4;
}
这样 本来要循环 100 次 ,经过 上面处理, 就只需要循环 25 次
每轮循环 加多少次 由编译器 和 循环终值 决定
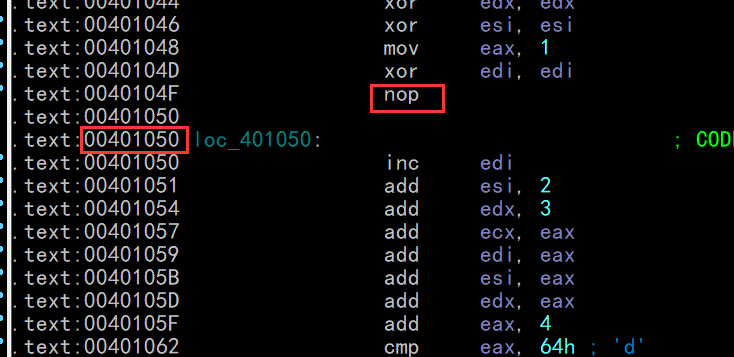
nop 等价的指令有很多 mov eax,eax xchg eax,eax 等等
让循环首地址 在 %16 = 0 的位置 ,这样访问更快,因此内存寻址更方便
整形数组寻址是,如果地址不是 四的倍数 ,那么 取值是就要取相邻2个地址的值,通过位运算 获得 需要的值
例如 : 00400002 地址的值 ,需要 00400000 的 后两位 + 00400004 的 前2位的值 ,因此需要先取出 00400000 和 00400004 处地址的值,在通过位运算得到我们想要的值 , 但是如果在 % 4 = 0的 地址,就只需要取一次,就可以减少开销
数组寻址公式: (int) ary + sizeof(type)*n
管理单位带来的有点: 在存储地址的时候可以忽略低位, 例如,保存一个32位的地址需要32跟地址线,四字节对齐值后就只需要 30 根地址线 ,(低2位是0), 另外2根地址线用来表达地址权限了,(0环 或者 3环)


 雷达卡
雷达卡 发表于 2025-5-5 11:53:52
发表于 2025-5-5 11:53:52
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶